Causal inference
Survivorship bias
- Survivorship bias is when being sampled is predicated on some other selection process
- For instance, suppose you were interested in the effects of gentrification and displacement on mental health in a particular community
- You might go door-to-door surveying residents of that community
- Who would you miss?

Correlation does not imply causation

© xkcd
Front-door and back-door paths
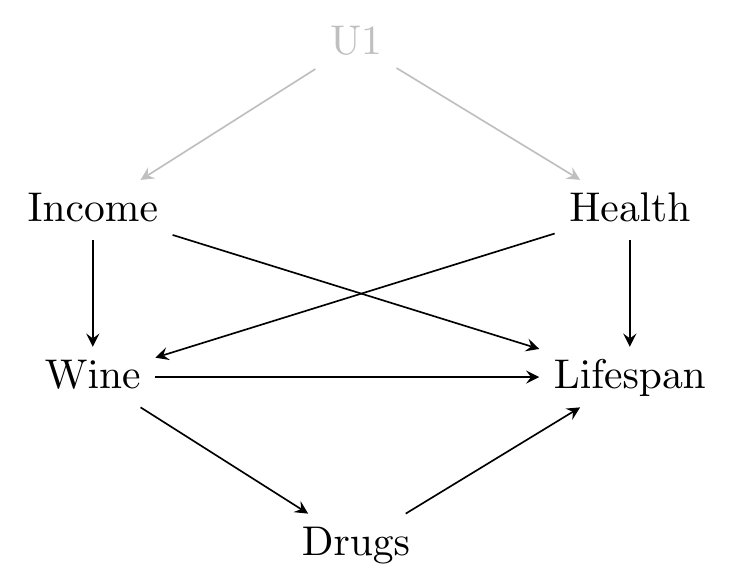
Huntington-Klein (2022)
The experimental ideal
- The “gold standard” is the randomized control trial
- You take your sample, and randomly divide people into the treatment group and the control group
- Because you divided the sample randomly, the only difference between the treatment and control group is whether they received the treatment
- Do a hypothesis test, maybe a very simple regression, and you’re done
Regression discontinuity, hypothetically
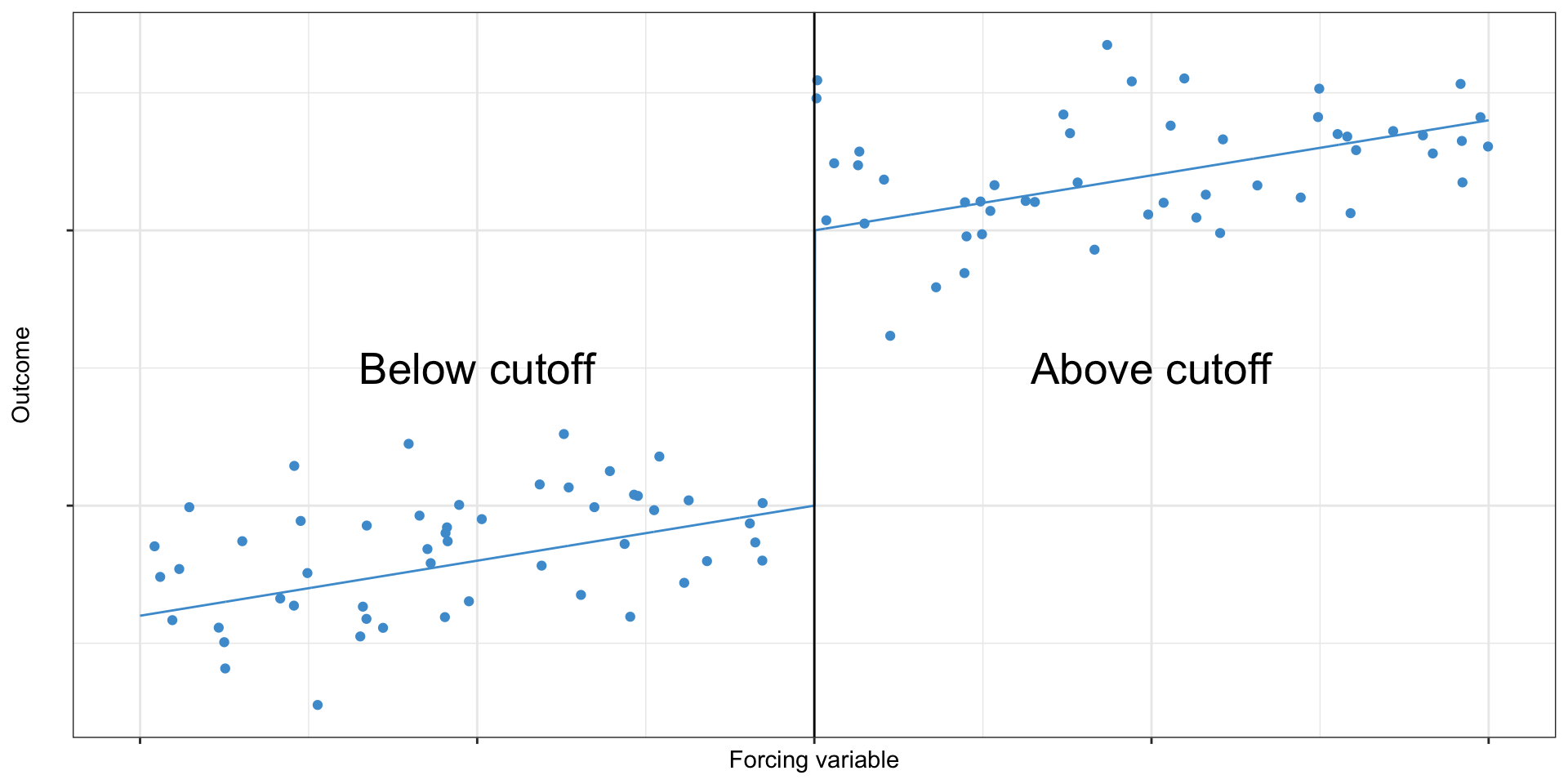
Regression discontinuity
- Airfares are generally more expensive at hub airports dominated by a single carrier (e.g. Atlanta, Charlotte, Newark)
- The AIR-21 act aimed to promote competition at these airports
- It applied to large airports where >50% of traffic is from one or two airlines
- Hubs are probably different from other large airports in all kinds of ways, but airports with 49% vs 51% of service from two carriers are probably pretty similar
- Snider and Williams (2015) uses this to find that the act reduced airfares 13–20% at these airports

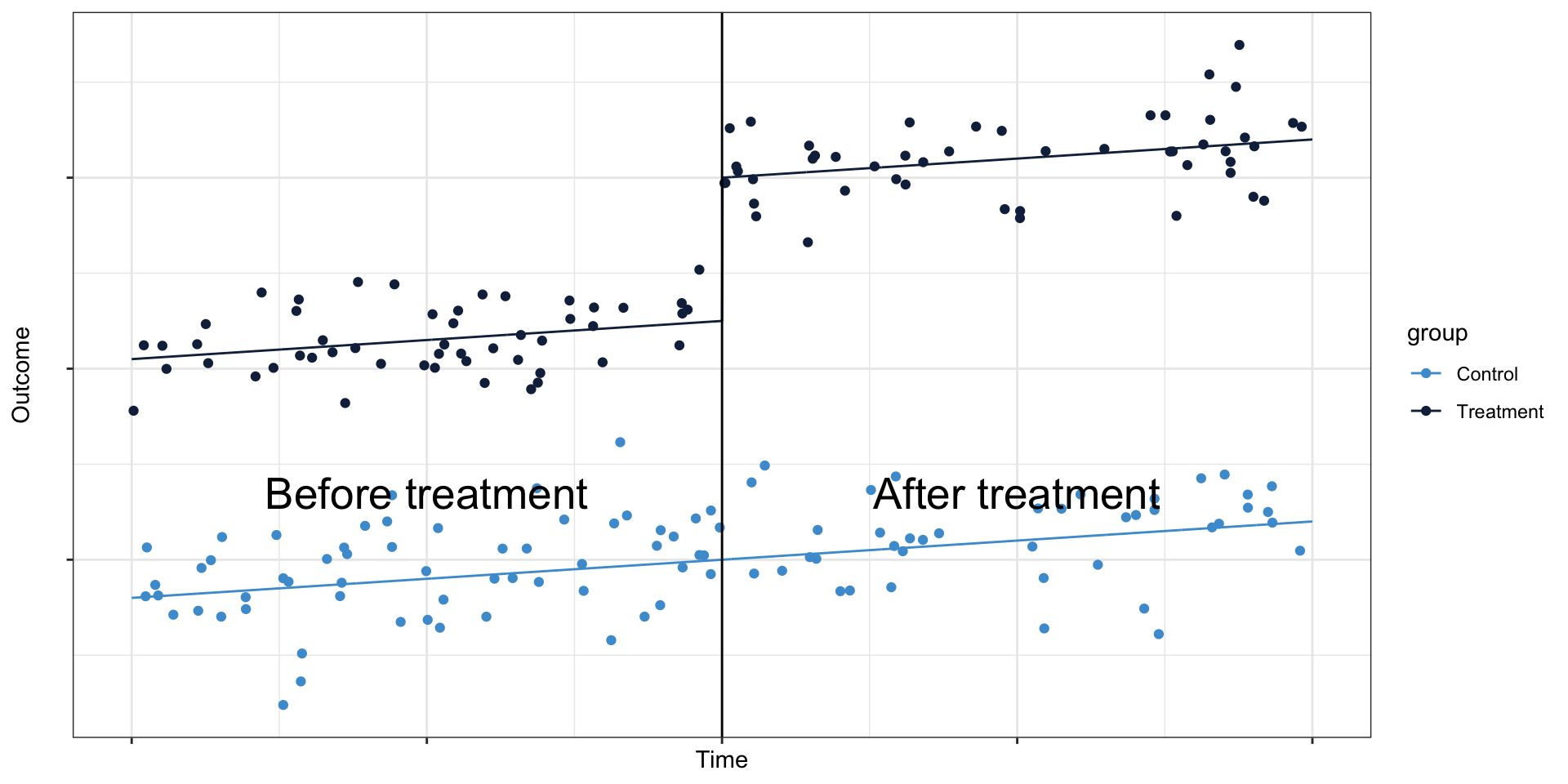
Differences in differences, hypothetically
References
Angrist, Joshua D., and Alan B. Krueger. 1991. “Does Compulsory School Attendance Affect Schooling and Earnings?” The Quarterly Journal of Economics 106 (4): 979–1014. https://doi.org/10.2307/2937954.
Bhagat-Conway, Matthew Wigginton, and Sam Zhang. 2023. “Rush Hour-and-a-Half: Traffic Is Spreading Out Post-Lockdown.” PLoS One.
Chetty, Raj, Nathaniel Hendren, and Lawrence F Katz. 2016. “The Effects of Exposure to Better Neighborhoods on Children: New Evidence from the Moving to Opportunity Experiment.” American Economic Review 106 (4): 855–902. https://doi.org/10.1257/aer.20150572.
Currie, Janet, and Reid Walker. 2012. Traffic Congestion and Infant Health: Evidence from E-ZPass. NBER Working Paper No. 15413. National Bureau of Economic Research. https://www.nber.org/system/files/working_papers/w15413/w15413.pdf.
Diamond, Michael S. 2023. “Detection of Large-Scale Cloud Microphysical Changes Within a Major Shipping Corridor After Implementation of the International Maritime Organization 2020 Fuel Sulfur Regulations.” Atmospheric Chemistry and Physics 23 (14): 8259–69. https://doi.org/10.5194/acp-23-8259-2023.
Huntington-Klein, Nick. 2022. The Effect: An Introduction to Research Design and Causality. First edition. A Chapman & Hall Book. CRC Press, Taylor & Francis Group. https://doi.org/10.1201/9781003226055.
Kaza, Nikhil, and Todd K. BenDor. 2013. “The Land Value Impacts of Wetland Restoration.” Journal of Environmental Management 127 (September): 289–99. https://doi.org/10.1016/j.jenvman.2013.04.047.
Leventhal, Tama, and Jeanne Brooks-Gunn. 2003. “Moving to Opportunity: An Experimental Study of Neighborhood Effects on Mental Health.” American Journal of Public Health 93 (9): 1576–82. https://doi.org/10.2105/AJPH.93.9.1576.
Ludwig, Jens, Greg J. Duncan, Lisa A. Gennetian, et al. 2013. “Long-Term Neighborhood Effects on Low-Income Families: Evidence from Moving to Opportunity.” American Economic Review 103 (3): 226–31. https://doi.org/10.1257/aer.103.3.226.
Salon, Deborah, Laura Mirtich, Matthew Wigginton Bhagat-Conway, et al. 2022. “The COVID-19 Pandemic and the Future of Telecommuting in the United States.” Transportation Research Part D: Transport and Environment 112 (November): 103473. https://doi.org/10.1016/j.trd.2022.103473.
Snider, Connan, and Jonathan W. Williams. 2015. “Barriers to Entry in the Airline Industry: A Multidimensional Regression-Discontinuity Analysis of AIR-21.” The Review of Economics and Statistics 97 (5): 1002–22. https://doi.org/10.1162/REST_a_00455.
Souza Briggs, Xavier de, Susan J Popkin, and John Goering. 2010. Moving to Opportunity: The Story of an American Experiment to Fight Poverty. Oxford University Press.

This work by Matthew Bhagat-Conway is licensed under a Creative Commons Attribution 4.0 International License.